What Is a Sales Knowledge Lake and Why Does It Matter for AI Agents?
June 17, 2026



A Sales Knowledge LakeTM is a governed, unified knowledge foundation that gives AI agents one accurate, approved source to answer from. Without it, an AI agent running on a website, in email, or across any buyer touchpoint is reasoning from whatever data it can reach, which means inconsistent answers, improvised pricing claims, and no audit trail. The Sales Knowledge LakeTM is what makes the difference between an AI agent you can trust in front of buyers and one you can't.
The key word is governed. A knowledge lake is not a bucket where you throw documents. It is a structured layer where data is ingested, deduplicated, cleaned, versioned, and made queryable in a way that an AI agent can reason from and not just retrieve.
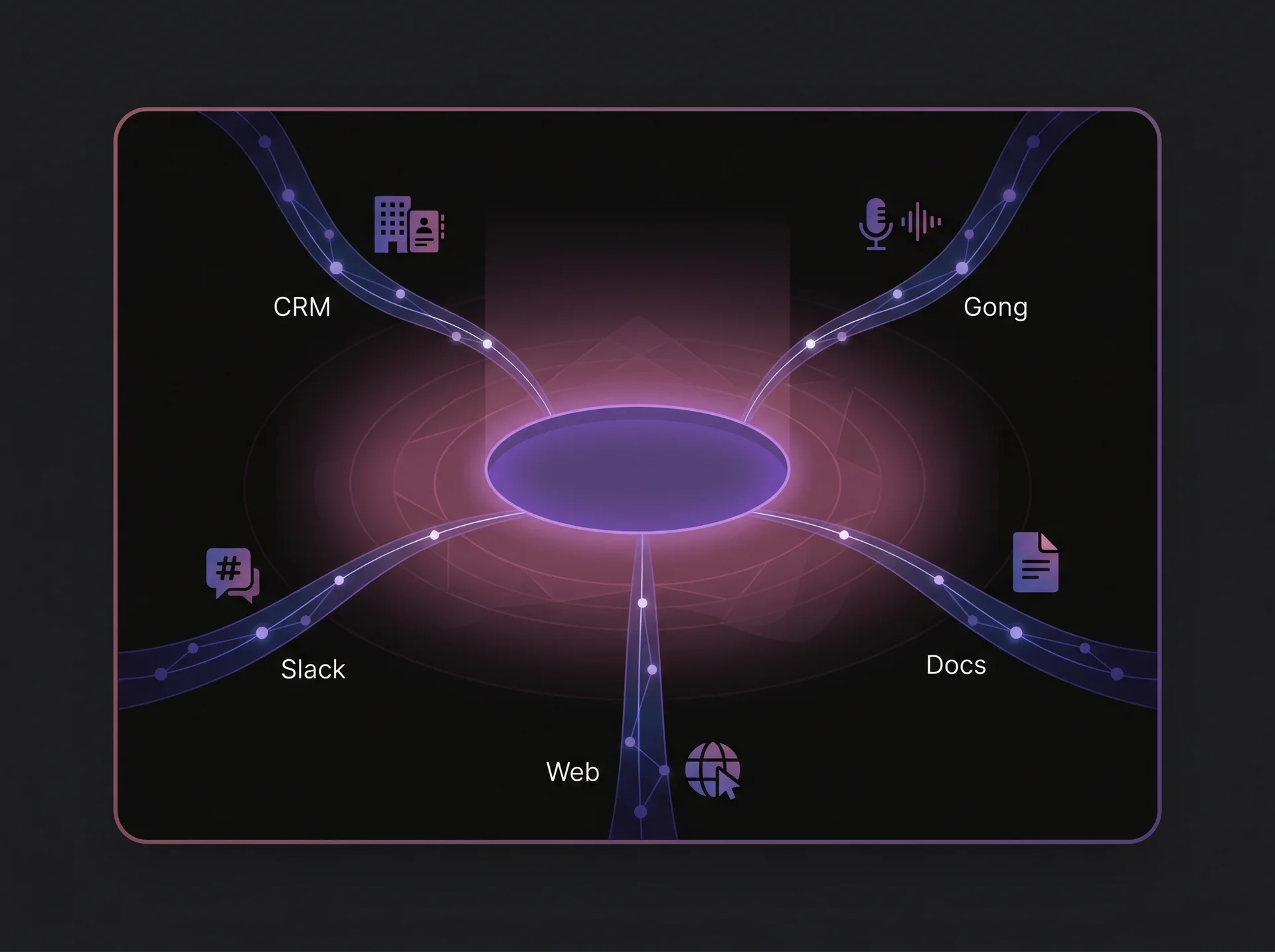
Docket's Sales Knowledge Lake™ pulls from five categories of sales-critical data:
On top of these structured categories, the Sales Knowledge LakeTM also ingests tribal knowledge: insights from your best sales engineers, call recordings from Gong, Slack conversations where reps solved hard problems, and enablement content that never made it into a formal document. This is the institutional knowledge that typically lives only in people's heads and disappears when they leave.
The distinction matters because most teams already have a knowledge base, which is a collection of documents in Notion, Google Drive, Confluence, or a sales enablement platform. When they hear "Sales Knowledge LakeTM," they reasonably wonder if they are being asked to rebuild something they already have.
They are not. The difference is not in what is stored. It is in what happens to the data before an agent can use it.
A knowledge base answers the question: "Where is this document?" A Sales Knowledge LakeTM answers the question: "What is the accurate, approved answer to this buyer's question, right now?" Those are different engineering problems with different architectures.
The Docket Sales Knowledge Lake™ is built in three stages. Understanding each stage makes clear why the output is structurally different from connecting an LLM to a folder of documents.
Docket connects to 100+ data sources natively: your CRM, marketing automation platform, Gong, Slack, Google Drive, SharePoint, sales enablement tools, website content, and more. The ingestion layer is not a search index. It is a unification layer that pulls structured data (pricing tables, qualification criteria, product specs) and unstructured data (call recordings, Slack threads, enablement decks) into a single pipeline.
This is where tribal knowledge gets captured. Most AI agents skip this step entirely, which means they cannot access the institutional knowledge that actually differentiates your product answers from a generic LLM response.
Raw data is not usable by an AI agent. It contains duplicates, contradictions, outdated versions, and noise. Docket's proprietary cleansing layer removes noise, deduplicates content, applies recency weighting (a document updated last week is ranked above one from two years ago), and resolves contradictions.
The output is structured into a Knowledge Graph: a representation of interconnected knowledge around your products, customers, competition, deals, and market. The graph is what enables an agent to reason across data points, thus connecting a buyer's question about an integration to the relevant security documentation and the relevant customer case study simultaneously, rather than returning whichever document scored highest in a keyword search.
The Sales Knowledge LakeTM is not static. It learns continuously from buyer conversations, expert feedback, and updated data sources. When a buyer asks a question that wasn't answered well, that gap feeds back into the knowledge layer. When a product manager updates the pricing deck, the knowledge is refreshed overnight. The governance layer stays current without manual re-ingestion.
This is what prevents the governance failure mode where an agent deployed on correct data in January is giving wrong answers by March because the product changed and nobody updated the bot.
An AI agent deployed on a website, in an email sequence, or in a live buyer conversation faces a challenge that internal tools don't: the buyer notices when the answer is wrong.
A rep using an internal AI copilot can catch a bad answer before it reaches the buyer. An autonomous agent talking directly to a prospect cannot. The accuracy of the answer is the product.
This is why the knowledge layer is not a nice-to-have. It is the architecture decision that determines whether an enterprise can deploy an AI agent in a customer-facing context without risk.
An AI agent running on an unstructured document store retrieves the closest match to a buyer's question. If your pricing changed last quarter, the agent retrieves the old pricing doc. If two product documents contradict each other, the agent picks one. If your best sales engineer's answer to a competitive objection is in a Slack thread from 18 months ago, the agent never finds it. The buyer gets an answer. It may not be the right one.
Docket's Sales Knowledge Lake™ solves this at the architectural level:
The level of enterprise control we have over accuracy and routing is exactly what we needed.— Olivier Roth, Co-Founder & Chief Growth Officer, The Swarm
In just two weeks, Docket's AI agent generated 23 meetings; over five times our baseline conversion rate. 100% answer accuracy across 192 conversations.— VP Marketing, A B2B marketing analytics company
Retrieval-Augmented Generation (RAG) is a widely used technique that improves LLM accuracy by retrieving relevant documents before generating a response. Most AI agent vendors use some form of RAG. That does not mean they have a Sales Knowledge Lake.
Standard RAG retrieves documents. The Sales Knowledge Lake reasons from structured knowledge. The distinction:
Answering competitive questions, pricing scenarios, security objections, and integration specifics correctly under live buyer scrutiny is not solved by generic RAG. It is solved by a knowledge architecture purpose-built for sales contexts.
The Sales Knowledge Lake™ is the foundation. It does not itself engage buyers. The agents that sit on top of it do.
Docket's agentic layer is an abstraction for building AI agents on top of the Sales Knowledge Lake™. The same governed knowledge foundation powers every agent deployed including website conversations, email sequences, event interactions, and more. Each agent can be configured with per-agent directives (which knowledge subsets it can access, what it escalates, how it qualifies) without rebuilding the knowledge layer for each one.
This is why enterprises can scale from one agent to many without the governance layer fragmenting. The knowledge is unified once. The agents draw from it differently, according to their configured scope.
In practice, this means:
For technical questions, SCs were spending unmeasurable time digging up answers. We had 12 SCs working on upwards of five questionnaires a week. Now we have a single, centralized source able to scale and handle what 12 people were doing. — Jack Torlucci, Senior Director, Solutions Consulting, Demandbase
A B2B data governance company deployed Docket's AI Marketing Agent on their website. In a two-week window, the agent reached 6,288 visitors and ran 62 real buyer conversations. Not form interactions, not support chats. Actual evaluation conversations where buyers were assessing fit.
The meeting book rate was 28.2%, which is 5.6x above the baseline. The Sales Knowledge Lake was what made that possible: the agent was answering questions about Adobe AEM integration, data migration complexity, and multi-team governance challenges accurately, in real time, without a human in the loop.
More importantly: the agent surfaced a buying signal that no other analytics tool had ever caught. Adobe AEM integration was the single strongest predictor of purchase intent in their buyer conversations. This pattern is invisible in form data and page views, but visible in actual conversation content.
Docket doesn't just capture leads — it gives us intelligence. We now know AEM integration is our strongest buying signal, and we have clear visibility into where prospects stall in the funnel. — Enterprise Marketing Leader, A B2B data governance company
No. A knowledge base stores documents. A Sales Knowledge Lake processes those documents through proprietary cleansing, deduplication, and a knowledge graph so that an AI agent can reason from structured, accurate knowledge rather than searching and returning the closest document match. The governance and accuracy properties are different.
Docket connects your data sources and completes the initial knowledge build in hours, not weeks. White-glove onboarding connects your CRM, Gong, Google Drive, and other sources, runs preprocessing overnight, and delivers verified answers ready for production. The total customer configuration time is approximately four to six hours.
Docket connects to 100+ native integrations including Salesforce, HubSpot, Gong, Slack, Microsoft Teams, Google Drive, SharePoint, Notion, Confluence, Highspot, Seismic, and your website content. Structured data (pricing tables, qualification criteria) and unstructured data (call recordings, Slack threads, enablement decks) are both ingested and processed.
No. Docket will never use your data to train its models or enhance other customers' answers. Your data is isolated within your own Sales Knowledge Lake instance. It is not used to improve the shared model and is deleted upon contract termination.
When a buyer's question falls outside the approved knowledge boundary, the agent does not improvise. It escalates to a human, triggering a real-time Slack alert to the right rep with full conversation context before they join. The governance layer makes escalation the default response to uncertainty — not hallucination.
Docket runs nightly recrawls across all connected data sources. When your pricing deck, product documentation, or competitive positioning changes, the knowledge refreshes automatically. You do not manually re-ingest. The agents that draw from the Sales Knowledge Lake receive the updated knowledge on the next cycle.
Yes. Per-agent directives allow you to scope each agent's knowledge access differently. A pricing page agent can be restricted to approved pricing documentation only. A general product page agent can access the broader product and security knowledge. The governance layer does not require every agent to have access to everything.
Your AI agent is only as accurate as what it knows. See the Sales Knowledge Lake™ in action.